Lets start somewhere. 11,000 years ago. The Ice Age has long gone, humans have started hunting and gathering in groups. We have not yet invented agriculture. To the West, the first stone walls of Jericho are being stacked, and in Turkey, the hunters of Göbekli Tepe are carving massive predatory totems (Schmidt, 2000).
In the subcontinent, things are interesting. On the Ganga Plains (modern-day UP) live the Titans of Sarai Nahar Rai. These are robust hunter-gatherers, some standing over six feet tall, who are already honoring their dead with red ochre and ritual burials — perhaps the first hints of an ancestor cult (Kennedy et al., 1986; Misra, 2001).
Along the “Teri” (red sand dunes) of coastal Tamil Nadu, specifically around Tuticorin, a specialized culture is grappling with a planet in flux. As the glaciers melt, sea levels rise, swallowing the land bridge that once connected India to Sri Lanka. These foragers don’t retreat.
At the center of the subcontinent, something different is happening. At Bhimbetka, rock art is transitioning from simple linear figures into complex depictions of communal dance and mythical animals (Mathpal, 1984). This is the birth of visual vocabulary and expressive creativity, especially in the subcontinent.
It is 1982. G.R. Sharma and J.D. Clark, leading a joint Indo-American team with J.M. Kenoyer and J.N. Pal, stand over a site known as Baghor 1, on the banks of the Son River Valley. Near Medhauli Village, Sidhi District, Madhya Pradesh.
They are looking for upper palaeolithic tools and instruments. They find something else that changes the entire understanding of religion, practices and culture.
They uncover a circular platform of sandstone rubble, about 85 cm across. At its dead center sits a single, natural triangular stone — hand-sized, just 15 cm tall. It’s vibrant, with concentric rings of yellow and ochre laid down by millions of years of geology, the surface itself daubed with pigment by human hands (Kenoyer et al., 1983).
The stone is a natural, laminated ferruginous triangle. Found in a Late Upper Paleolithic context, it is carbon-dated to ~9,000–8,000 BCE. The stone has probably been dug up and selected. It hasn’t been carved.
The structure looks like a place where a ceremony or worship has taken place. The stone at the center, complex in structure. When some tribesmen walk into the excavation, they see two excited archaeologists losing their minds over their discovery. The tribesmen belong to the Kol and Baiga tribes of Madhya Pradesh, one of the oldest tribes of the subcontinent.

They look at the artifact on the platform and are perplexed why everyone is so excited. The artifact is simply a khari, the Mother or Shakti. They still worship in that valley today, in that exact form (Kenoyer et al., 1983).
The Vedic religious tradition has roots in the Indo-Iranian language family and arrives in the subcontinent much later (Bryant, 2001). Between the Baghor site and the spread of Vedic religion, there is a 7,500-year gap. Let that sink in. Organized, named religion isn’t as old as this gap. The Indus Valley Civilization and Mesopotamia come 5,000 years later. Organized religion forms much later. This is at a time we do not even know how to write.
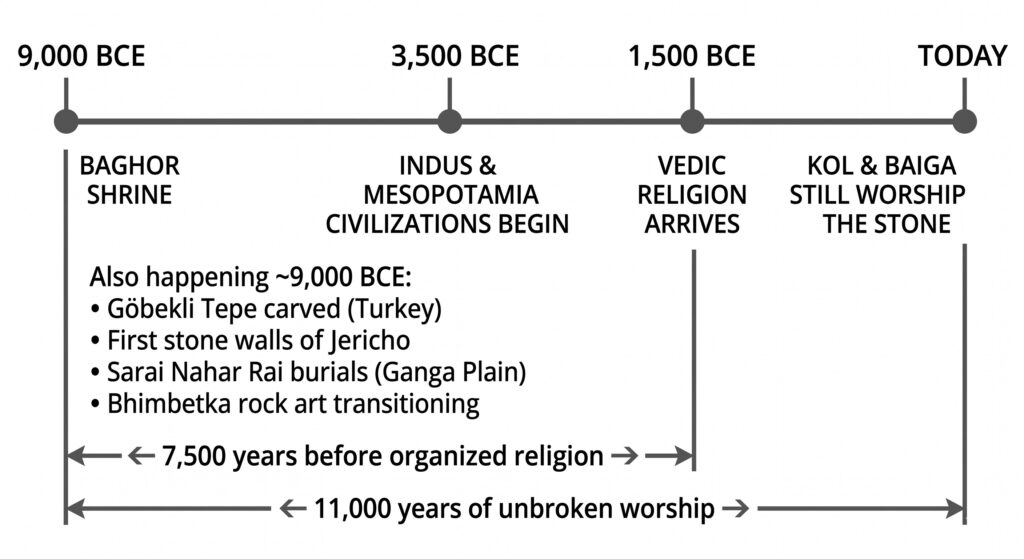
So what we can derive from this is that the earliest known form of worship in India centered on the mother or the female. Other parts of the world had ritualistic practices with different motifs — the predator totems of Göbekli Tepe in current-day Turkey, for instance.
Religion later coerced or adopted the culture of the land. That is how the practice has survived this long without written knowledge.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
YEARS AGO EVENT
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
│
300,000 ────┤ Modern humans emerge in Africa
┊
┊ ~230,000 years of foraging
┊
70,000 ────┤ Modern humans reach South Asia
┊
┊ ~30,000 years of dispersal across Eurasia
┊
40,000 ────┤ Upper Paleolithic begins
│ Venus of Hohle Fels carved (Germany)
│
30,000 ────┤ Chauvet Cave painted (France)
│ Engraved ostrich eggshell at Patne (India)
│
25,000 ────┤ Venus of Willendorf carved (Austria)
│
20,000 ────┤ Last Glacial Maximum — ice sheets at peak
│
17,000 ────┤ Lascaux Cave painted (France)
┊
┊ ~5,000 years of warming
┊
12,000 ────┤ Holocene begins. Ice Age ends.
│ Sea levels rising rapidly
│
11,500 ────┤ Göbekli Tepe construction begins (Turkey)
│
11,000 ────┤ ★ BAGHOR SHRINE
│ Sarai Nahar Rai burials (Ganga Plain)
│ Bhimbetka rock art transitions
│ First stone walls of Jericho
│
10,500 ────┤ Agriculture takes hold in Fertile Crescent
│
9,000 ────┤ Mehrgarh founded — farming reaches subcontinent
│ Çatalhöyük begins (Turkey)
│
7,000 ────┤ Pottery and settled villages spread
│
6,000 ────┤ Sumer founded — first cities
│
5,000 ────┤ Writing invented in Sumer
│ Early Harappan begins
│
4,500 ────┤ Mature Indus Valley Civilization
│ Egyptian pyramids built
│
3,500 ────┤ Vedic religion arrives in subcontinent
│ Rigveda composed
│
2,500 ────┤ Buddha. Mahavira. Greek philosophy.
│
2,000 ────┤ Roman Empire at peak
│
1982 CE ──┤ Sharma and Clark uncover Baghor 1
│
Today ──┤ ★ KOL & BAIGA STILL WORSHIP THE STONE
│
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Baghor → Vedic religion arrives: 7,500 years
Baghor → Today: 11,000 yearsReferences
Bryant, E. 2001. The Quest for the Origins of Vedic Culture: The Indo-Aryan Migration Debate. New York: Oxford University Press.
Kennedy, K.A.R., N.C. Lovell, and C.B. Burrow. 1986. Mesolithic Human Remains from the Gangetic Plain: Sarai Nahar Rai. South Asian Occasional Papers and Theses No. 10. Ithaca, NY: Cornell University South Asia Program.
Kenoyer, J.M., J.D. Clark, J.N. Pal, and G.R. Sharma. 1983. “An Upper Palaeolithic Shrine in India?” Antiquity 57(220): 88–94. https://doi.org/10.1017/S0003598X00055253
Mathpal, Y. 1984. Prehistoric Painting of Bhimbetka. New Delhi: Abhinav Publications.
Misra, V.N. 2001. “Prehistoric Human Colonization of India.” Journal of Biosciences 26(4): 491–531. https://doi.org/10.1007/BF02704749